
Introduction
Fuzz testing is a well-established testing technique which feeds software under test with pseudo-random input data. That data may uncover buffer overflows or similar bugs which are hard to detect by functional tests.
Coverage-Guided Fuzzing tracks the software execution path on any given input and uses this information for generating new input data. Thereby, it replaces random and undirected test data generation by a more effective, directed approach which maximizes the coverage of the tested software and thus the likelihood of finding bugs.
Projects like EB tresos ACG do not deliver a single monolithic piece of software, but several composable software modules. Each of these modules can be tailored to meet specific needs, e.g. by turning off features that are not needed and getting reduced processor load and/or memory footprint in return. Fuzz testing multiple tailored variants of each of the modules requires the compilation and execution of several thousand binaries daily, which can only be accomplished by automating this task and integrating it into the existing Continuous Integration/Continuous Delivery (CI/CD) tool chain.
EB’s Fuzz test automation system serves two main purposes:
- Detecting bugs as soon as possible and giving developers as much information as possible to fix them, thereby following the “shift left” paradigm.
- Generation of test metrics which provide an indication on the effectiveness of the Fuzz tests
Automated Fuzz Test Execution
After a build server finishes its daily build, it triggers a separate task which collects, for each module variant, the sources needed to compile the corresponding fuzz test, and puts them into a job archive along with meta-data, for instance the git version of the tested module. It then passes these job archives to one of several dedicated Fuzz servers.
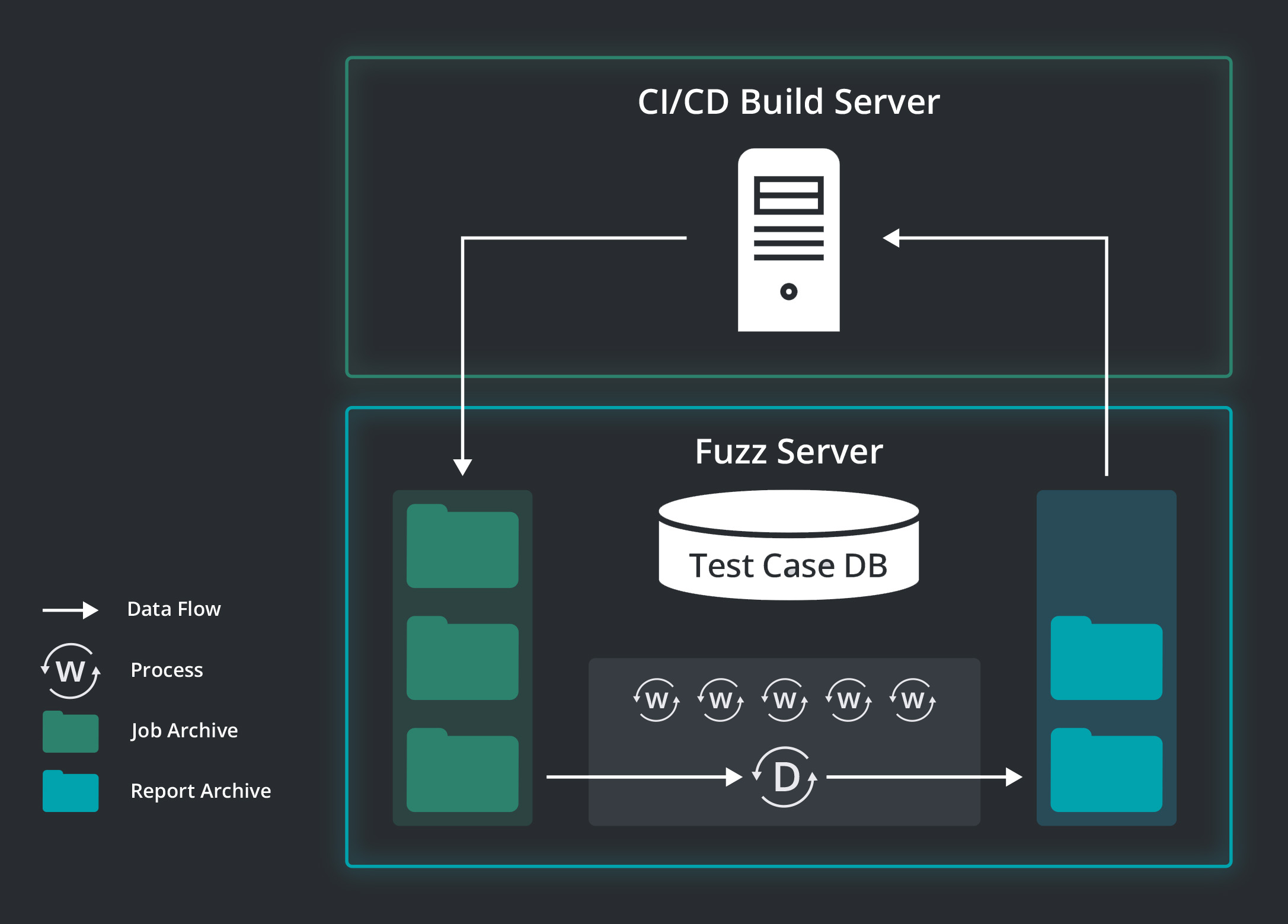
On the Fuzz server, a dispatcher process and several worker processes are executing. Upon the arrival of a job archive the dispatcher extracts it and distributes each contained variant to one of the worker processes, which then compiles the test binary and executes the Fuzz tests. A test binary contains the software module under test in a given variant and the Fuzzer code which reads or generates test data and passes it on to the software module under test. A worker process executes a Fuzz test by:
- Taking previously generated test data sets (also known as CORPUS) from a Test Case Database
- Executing the test binary for a defined amount of time and feeding it with the test data sets
- Merging the new test data sets, which the test binary generated, with the previously generated ones and storing the merged set in the Test Case Database
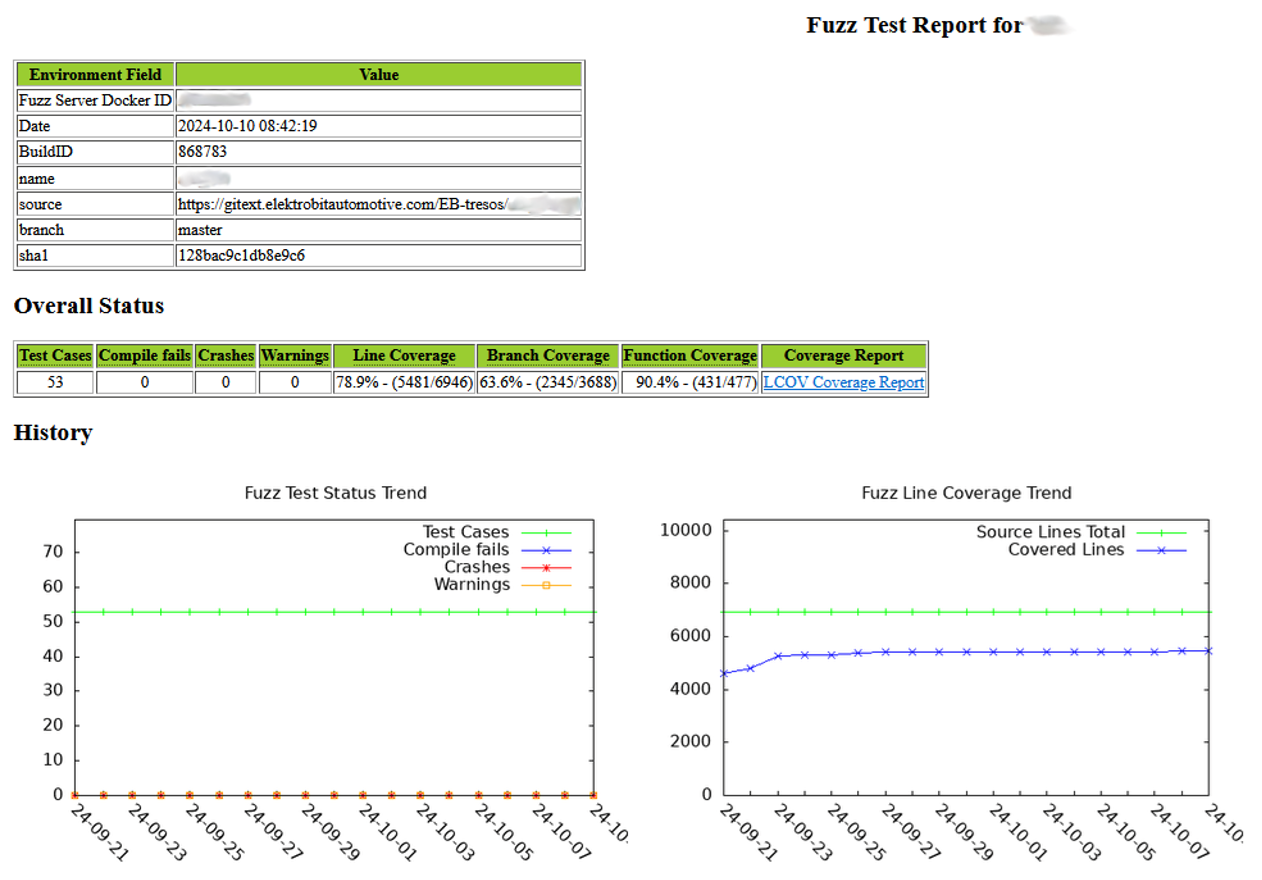
Whenever a worker process has finished, the dispatcher passes the next pending variant until all variants of a module have been processed. In the last step, the log files the Fuzz tests have generated are parsed and the information for generating the test report is extracted. This comprises:
- Compiler errors for each variant that did not compile
- Error messages and stack traces for each detected bug, along with generated C test functions that contain the sequence of the function calls into the tested module up to the point where a bug was detected. These functions can be compiled and run on a conventional development environment (i.e. one that does not need to have the software for executing the Fuzz tests installed).
- Coverage metrics
Once the report is generated, it is put it into a report archive and the CI/CD server which triggered the Fuzz tests is called back that a test report is available. That server picks up the test report and makes it available to the developers.
Whenever no jobs are pending on a Fuzz server, its dispatcher process selects previously processed jobs and passes them on to the workers to generate additional test data sets. Thereby it uses the processing capacity of the hardware 24/7 and increases the likelihood of finding additional bugs.
Conclusion And Outlook
- Employing Coverage-Guided Fuzzing helped the EB tresos ACG project to discover and fix a significant number of cybersecurity-related issues which conventional test methods did not find.
- By automating the Fuzz test execution, we detected the issues early in the development process. This allowed us to fix them almost immediately after injection. This, in turn, made the bug fixing process more effective and cheaper.
- Observing the test metrics lets us evaluate whether module code is sufficiently covered by the Fuzz tests.
- Currently, a Fuzz test run on a server executes ~2500 variants of ~60 modules in roughly 3 hours, which -in the moment- meets our requirements.
- The resulting test system consists of a few scripts running in a Docker container. Building such a lean system was possible since we knew the requirements for the test automation system very well.
For the next few months, we expect that additional Fuzz tests will be added, and therefore additional load on our Fuzz server infrastructure. Since it is very lean, we can either extend it easily or switch to a more powerful system once that is necessary
Author

Ernst Schwaiger
Senior Expert, Car Infrastructure Software

